How We Made our Rich Text Editor Load Faster - Part 2

In part 1 of this blog series, we looked at the performance impact that CKEditor was experiencing when loading huge documents after we re-architected the solution (If you missed that post, now is the time to back up and check it out).
Now, in part 2, we’ll take a deep dive into our optimization process and see how we went about addressing these challenges. We’ll also talk about the results of the changes, and what we learned along the way.
The Big Wins
So, what did we actually do?
Based on our knowledge, and supported by the performance profile reports, we came up with two clear major areas to explore. Both these cases shared similarities. They are actions performed a huge number of times, and during these actions, we evaluate the same values over and over again. Both actions are core, internal, editor-wide mechanisms, used by the majority of the rich text editor features. It would be risky and time-consuming to replace them with a different solution.
These two actions were good candidates for improvement with a caching mechanism. It resulted in lowering editor load time by around half for each case, to almost a 75% lower total load time.
On top of that, we implemented several other, smaller, targeted fixes for specific features or scenarios. This, too, cut the loading time by half, and helped us reach almost 85% lower total load time.
It’s time now to dive into the two most impactful changes. On the surface, we just cached things. But we will dive deeper into the problems and into the CKEditor architecture to discover the complex nature of this subject.
Calculate the Position of a Child Inside its Parent
The editor data model is a tree structure with parent elements that may have children nodes (usually text). Characters are organized into text nodes. Each text node is a single object that groups all consecutive characters that have the same set of attributes (e.g. formatting). Naturally, text nodes have various lengths.
All text nodes inside their parent element are stored in an array. In a typical document, a paragraph would have from one up to a few children, depending on how the text is formatted. However, in some specific cases you might have many, many children in one paragraph – for example, if your application needs to attach some metadata to each word.
The described model can be simplified to the following structure:
{
"element": "paragraph",
"children": [
{
"text": "This is ",
"attributes": []
},
{
"text": "formatted",
"attributes": [ { "bold": true, "italic": true } ]
},
{
"text": " text",
"attributes": [ { "bold": true } ]
}
]
}
This structure has an obvious limitation: you cannot easily retrieve a character at an arbitrary position. For example, there’s no fast way to tell what is the 12th character in the paragraph. Same the other way around – if we have a text node instance, we don’t know on which position it starts. We “ask” both these questions a lot, so it is important to get the answer quickly.
Until recently, we would simply iterate all the children starting from the first one, sum their sizes, and do it until the requested position has been reached. This, of course, means a lot of processing.
Two initial solutions that may come to mind are:
-
Keep every character as a separate object. However, this raises two problems. One is memory overhead. All properties that we now keep for a text node would need to be duplicated for each character instance. The other problem is… performance. In many cases, it is beneficial that we can iterate through whole text nodes in one step, instead of going through hundreds of characters one by one.
-
Cache some values to make it quicker to find the requested position.
Using cache, by definition, introduces a different problem – updating and cleaning the cache.
From a general perspective, there are various solutions to implement caching, and they differ depending on what you want to cache, and how you want to use cached values. You always need to choose between saving speed, reading speed, update speed, and code complexity, and sacrifice one for another.
In our case, we had a few choices:
-
Each child should keep its position (the sum of the sizes of all preceding children) as its own property. By itself, it doesn’t help much – you still can’t quickly retrieve a character at an arbitrary position. But it allows you to treat children positions as a sorted array, and use binary search to quickly find the child that overlaps the requested position. This lowers the retrieval time from linear to logarithmic complexity. Unfortunately, updating the cache is still linear. If you type a letter at the beginning of the paragraph, you need to refresh all text nodes positions.
-
Add another array representing children, where each index would be a reference to the child that occupies this position. It is the ultimate solution for reading the data – you simply read from an array, which is a constant-time operation. Cache update complexity is still linear – if something changes, you need to refresh everything. But… in this solution, it is linear depending on the total number of characters instead of number of children. Mind the difference: a paragraph may have hundreds of characters, but only one child text node, if they all have the same formatting. So this is much worse. It also adds substantial overhead on memory consumption.
-
Find a fitting data structure that would offer a logarithmic complexity both for read and for update operations. This isn’t simple, as we have some constraints to work with. The items that we store have various sizes, can change anytime, and we can add or remove items at any position. Additionally, we also want to quickly answer at which position a given child starts (this is the opposite question to “read from position X”, that we debated so far). Fortunately, a proper implementation of an AVL tree checks all the boxes. All the actions can be done in logarithmic time.
We ended up implementing the second solution. Outside the context, using an AVL tree is the best choice, as you have low times for all the actions. But we also considered some other factors.
First of all, in general, read actions are far more common in the system than insert/update actions.
Linear time for insertions (due to cache update) is brutal, but that’s just in theory. In reality, if you consider rich-text editors, the insertions usually happen at the end of a paragraph, as, well, users usually keep typing at the end of a paragraph. It is also a case for loading and saving a document – which was our main focus. So, we kind of got both constant speed for reads and for insertions.
Obviously, the first thing that we tested is the impact on typing at the start of a longer paragraph.
In all honesty – we expected typing performance to degrade so much that this solution wouldn’t be viable. We went with this implementation rather as a preliminary check – to confirm that lowering computational complexity in this area would have a significant impact on the editor’s performance. We thought that the AVL tree solution was superior, but we didn’t want to commit time to it without first making sure that caching would indeed solve the problem. Especially since our intuition failed us already in other areas.
In the end, we saw no negative impact on typing performance. As a result, we decided to keep this solution as the final one.
It needs to be noted that this solution does increase the editor’s memory consumption. In the world of optimization, it is a thousand-years-old battle between memory and processing performance, and oftentimes you are forced to choose between these two. We will monitor how this affects our customers’ applications.
In any case, we still have the AVL tree up our sleeves and thanks to a pile of automated tests and a proper abstraction layer over the internals, we can change the solution without hesitation, and without any backward compatibility concerns.
Improving Position Mapping from Model to View
Another place where we used caching is the mapping between the model tree and the view tree.
So far, we talked a lot about the model tree – our custom data structure which keeps document data, and the document data only. It’s simplified, compared to the DOM or the output HTML returned by the editor when data is saved. But the editor also maintains the “live” view tree structure, which is built from the model and is very close to the final DOM/HTML.
When a node changes in the model, the change is reflected in the view. Although we can easily map model elements to some of the view elements, the mapping process gets more complicated when text formatting or complex features are involved.
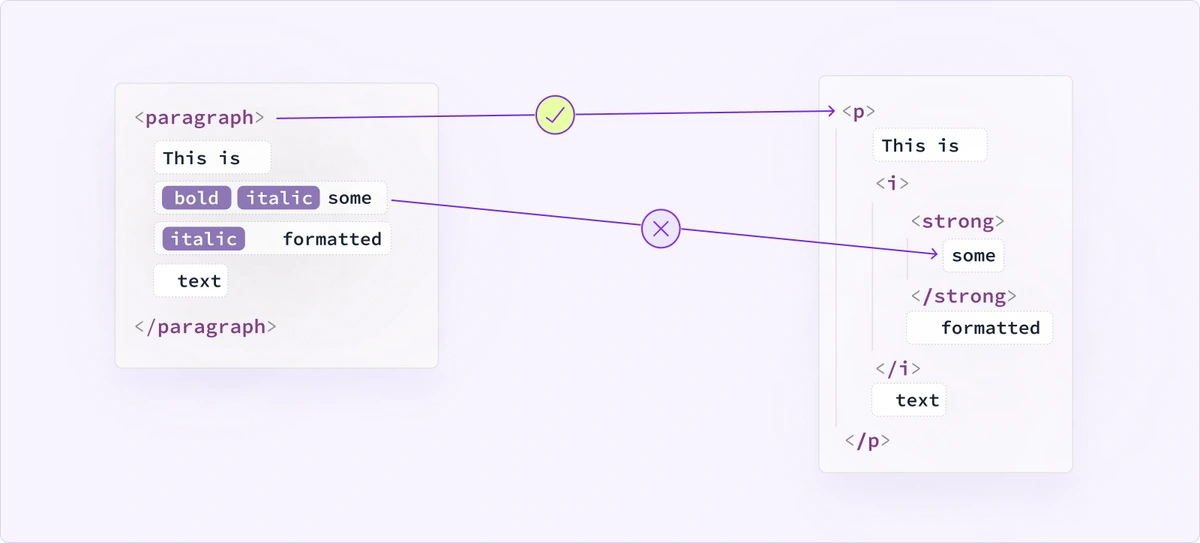
We can store which model and view elements are related. However, model text node instances are very volatile, often created, merged, split, and destroyed as the editor engine performs changes using the low-level API. Unfortunately, with the current architecture, we cannot store them and link them with their view counterparts.
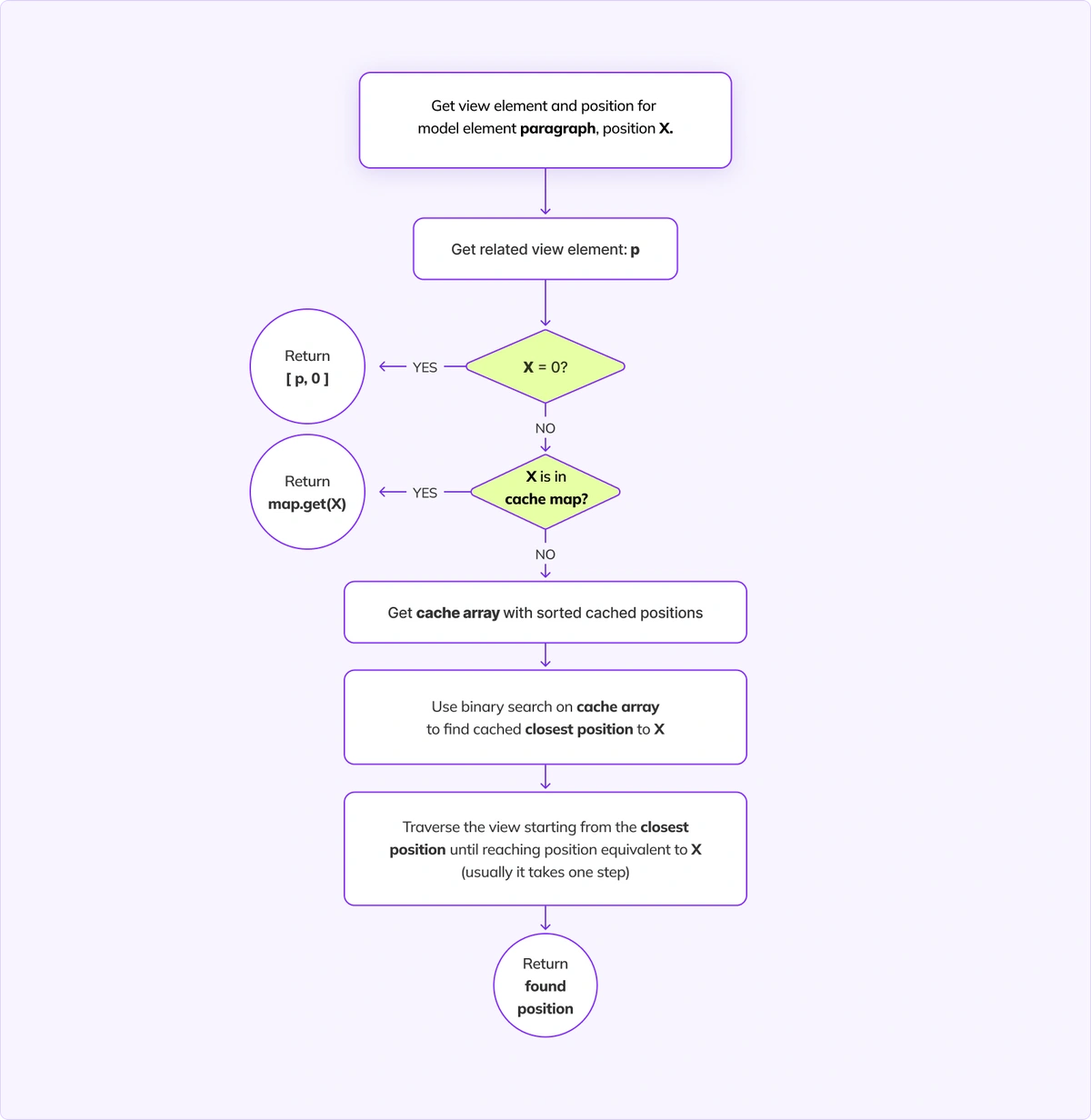
Very often we need to find a position in the view based on the position in the model. Since these structures may differ, we traverse from a “known” place (the beginning of a mapped view element) until we pass over the view nodes whose total size equals the position in the element in the model.
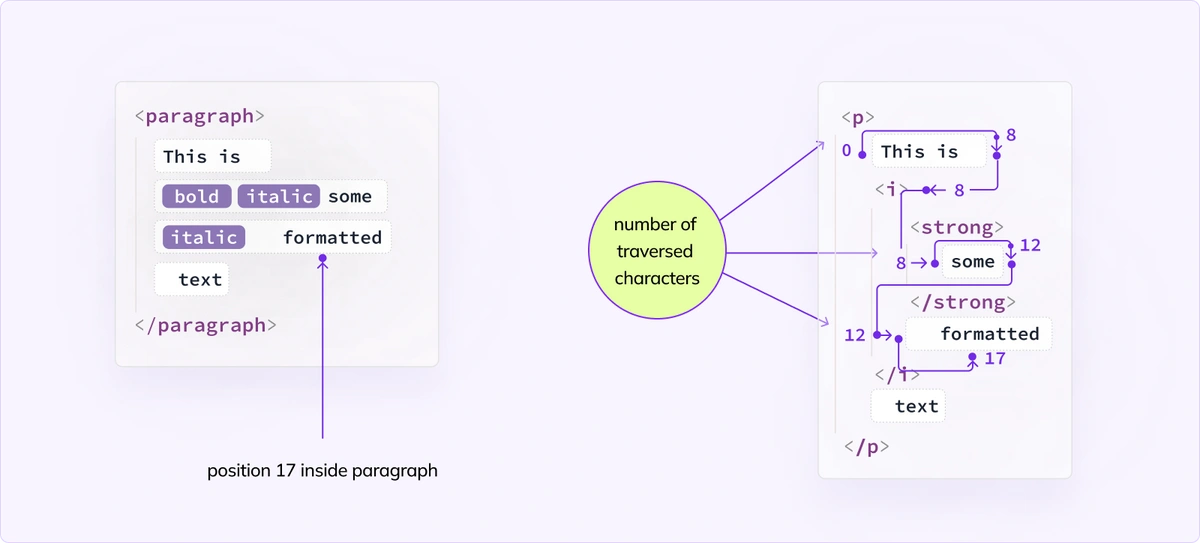
In this example, we look for position 17. We traverse the view until we pass 12 characters. The text node formatted is 10 characters long, so the position we look for is inside of it. We conclude that model position [ paragraph, 17 ] is equivalent to view position [ formatted, 5 ].
After implementing caching, we still traverse the view. But now, we cache earlier results so that we can either “answer” instantly, or start traversing from a closer, “known” place.
The model-to-view position mapping mechanism is more complex than retrieving a character at a given position, so the cache mechanism is also much more complex. Below we present the general concept.
First, let’s see which positions are equivalent between the model and the view:
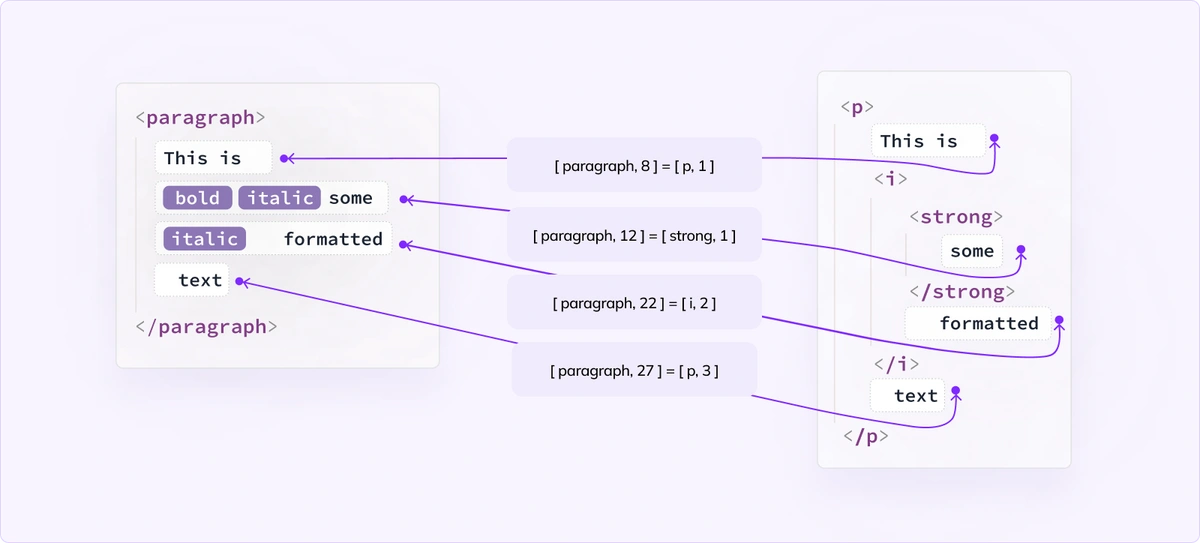
As we jump over text nodes in the view we sum their sizes in the model, and for each visited view position we save that number. We use two structures for this cache. For each model <-> view element pair, we have a Map and an array in which we keep the mappings.
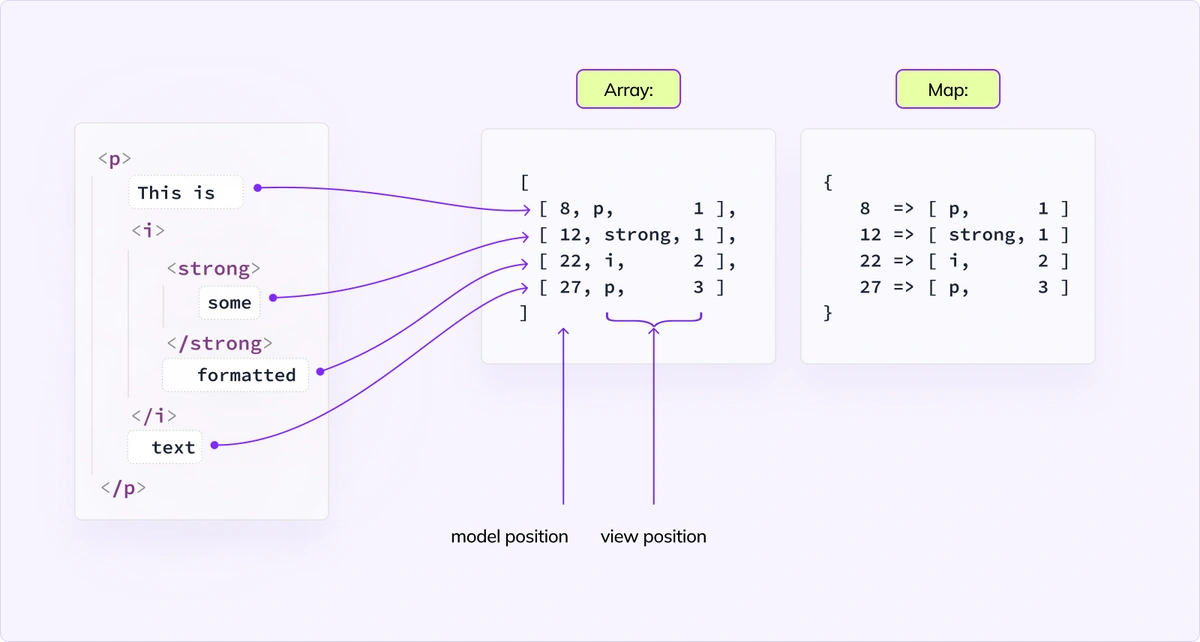
This time, we don’t store all possible positions, like we store “all indexes” in the first solution. Instead, we cache only positions after the nodes. To find an arbitrary position, we need to run a binary search on an array of cached positions, find the closest (lower) one, and make one, or just a few steps, to get the final result.
Using the example – if we ask for the model position [ paragraph, 25 ], we would find entry [ paragraph, 22 ] = [ i, 2 ], and continue from the <i> element to quickly find that position 25 is inside the view node “text”. Without cache, we would need to start traversing from the very beginning.
We again make use of the knowledge of how the editor works and what are the most common scenarios. When loading a document, it turns out that we most often ask about positions that are after a view node - the ones that we visit and store when traversing the view tree. To map them even faster, we utilize the Map structure. If the position is found inside the Map, we can return it straight away. This seems like a minor optimization, but retrieving an item from a Map should take close to a constant amount of time, and the difference between binary search and retrieving from a Map was visible in our performance tests.
Finally, as with every cache, you need to invalidate it. When there’s a change in any place in the view tree, we check where exactly this change happened (thanks to a smart trick, we can do it in a constant time), and remove all further entries from the cache array and the cache map.
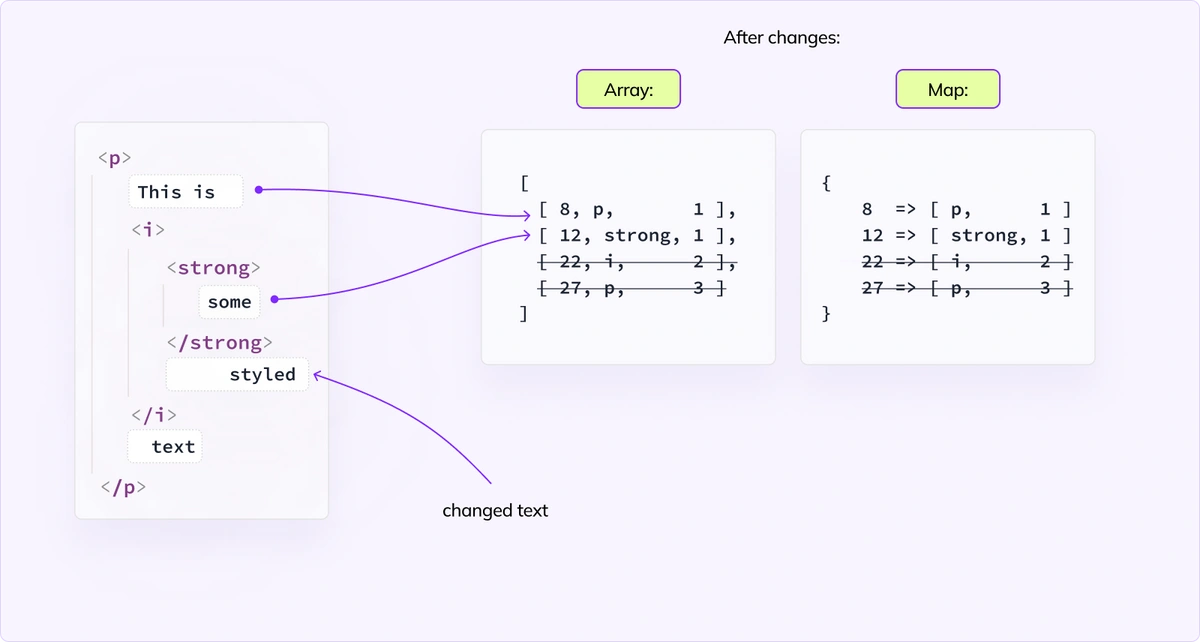
Next time we ask about position after “some” we traverse the view starting from the closest cached position (12) and rebuild the cache again.
Since we may revisit this solution, we put an effort to make sure it is as contained as possible. In the end, we managed to implement it as a private class, which use is contained just in one other class.
Lessons Learned
This was a very successful project for us, on multiple axes. We addressed one of the key pain points that affected our users’ experience. We not only greatly exceeded our expectations, but we achieved it through less complicated solutions than we initially assumed.
Plus, there are a few learnings from this story that we can share.
Take care of the optimization in a responsible way, and don’t wait until it is too late. Some optimization may be premature, but if your system relies on a few heavily used algorithms, test and fix them if needed before twenty other mechanisms start using them.
Profiler is an amazing tool and you can even use external tools to analyze profiles generated by the browser. However, you need to learn how to use it – the profiler won’t magically solve your issues on its own. Initially, you will find some easy and obvious spots to fix. If you are past that point, you have to combine the profiler results with your deep project knowledge. Your intuition can be invaluable. But be aware – it sometimes leads to wrong assumptions, so verify every single assumption you make.
When it comes to the execution time: “not doing anything” is the fastest “solution”. Hence, caching, despite being blunt and obvious, is so powerful. However, many times it comes with increased complexity and memory usage costs, so pick your battles carefully.
And finally, strong test coverage and a proper architecture are the enablers of any significant changes. We wouldn’t be able to risk meddling with critical pieces of the system if not for a multi-tiered, extensive test suite and application design that encapsulated fragments that required changes.
Next Steps
Although we are extremely happy with the results delivered in this project, we are also aware that the struggle is not over yet. We look forward to continuing the research in other areas, such as typing performance, performance of some specific features, or faster document saving.
When it comes to even bigger ideas, the already mentioned content streaming is an interesting avenue to explore. We avoided it several years ago, but the concept may be worth revisiting.
Another very promising idea is to use CKEditor’s internal data model as the document data, instead of saving and loading the HTML. The impact of this change would be significant for document loading time, however for the saving time it would be an astronomical difference – single-handedly resolving all autosave issues. However, that comes with a set of less desired consequences and is connected with several parts of our product’s ecosystem.
Performance is a topic that we keep on discussing internally. Be it big or small, we hope to bring you more happy news in future releases!
We encourage everyone to update to the newest CKEditor 5 version to benefit from the improved editor loading performance. If you still experience performance problems, please contact us through technical support. Learning about specific use cases gives us invaluable insight when we approach complex problems like the editor’s performance.